

Jak Apple dba o naszą prywatność i jednocześnie zbiera dane o sposobie użytkowania urządzeń i programów? W wyjątkowo zawiły dla laika sposób. Na szczęście inżynierowie Apple z Machine Learning Journal starali się wytłumaczyć to w możliwie przystępny sposób.
Wiedza o tym, jak używamy urządzeń, jest bardzo ważna.
Pozwala udoskonalać sprzęt i oprogramowanie, korygować błędy oraz rozpoznawać nowe trendy w sposobie używania urządzeń i programów.

Jak inżynierowie Apple piszą na blogu: „Uzyskanie wglądu w ogólną populację użytkowników ma kluczowe znaczenie dla poprawy komfortu użytkownika”. Przykładem niech będzie wykrycie częstych błędów związanych z pomyłkowym wybieraniem pierwszej „podpowiedzi” podczas używania angielskich klawiatur, o którym wspominają we wpisie autorzy. Jednocześnie zaznaczają, jak te dane są wrażliwe.
Anonimowość danych
Kluczowe są dwie kwestie: Dobrowolność i anonimowość.
Apple zawsze prosi o zgodę na przesyłanie danych z naszych urządzeń. Ręcznie możemy tym zarządzać w: Ustawienia -> Prywatność -> Analizy.
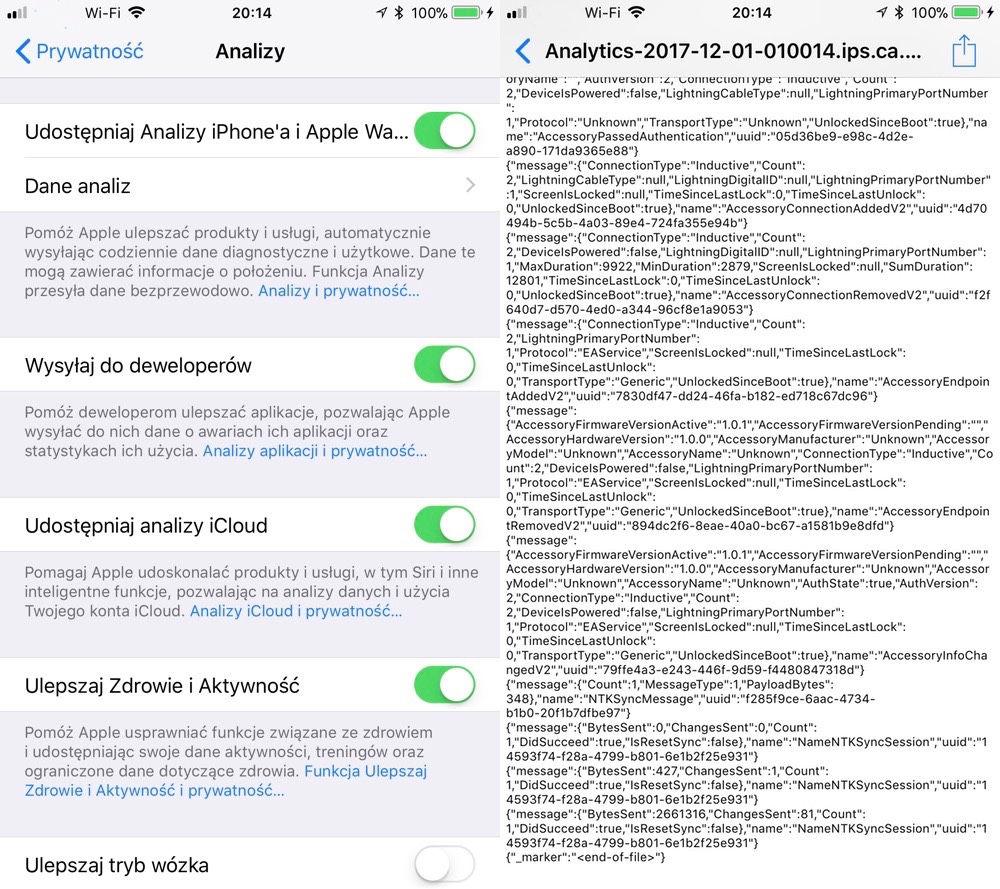
Gdy zdecydujemy się przesyłać dane, to możemy być spokojni o to, że będą one anonimowe i nie pozwolą na skojarzenie ich z naszą osobą. Jak to jest możliwe?
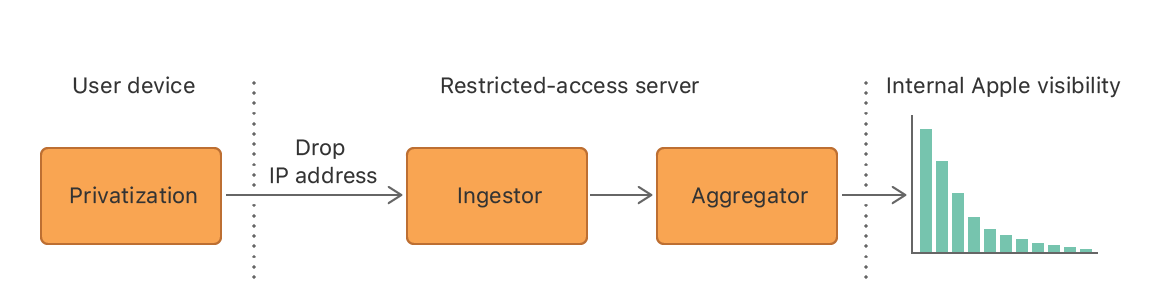
W przeciwieństwie do wielu innych firm, które zbierają dane w sposób „centralny”, Apple używa systemu „lokalnego”. Najlepiej niech spróbują to wytłumaczyć sami projektanci systemu.
Nasz system został zaprojektowany z myślą o świadomej zgodzie i przejrzystości. Żadne dane nie są rejestrowane ani transmitowane, zanim użytkownik wyraźnie nie zdecyduje się na przesyłanie informacji o użytkowaniu. Dane są sprywatyzowane na urządzeniu użytkownika przy użyciu prywatności różnicowej na poziomie zdarzenia w modelu lokalnym, gdzie zdarzeniem może być na przykład umieszczanie w tekście emotikonów. Dodatkowo ograniczamy liczbę transmitowanych sprywatyzowanych zdarzeń. Transmisja do serwera odbywa się za pośrednictwem zaszyfrowanego kanału raz dziennie, bez identyfikatorów urządzeń. Rekordy docierają do serwera o ograniczonym dostępie, gdzie identyfikatory IP są natychmiast odrzucane, tak jak wszelkie powiązania między wieloma rekordami, które również są odrzucane. W tym momencie nie możemy rozróżnić na przykład, czy rekord emoji i rekord domeny internetowej Safari pochodzą od tego samego użytkownika. Rekordy są przetwarzane w celu obliczenia statystyk. Te zbiorcze statystyki są następnie udostępniane uprawnionym zespołom w Apple.
Dodatkowym zabezpieczeniem jest dodanie do danych „szumu”, czyli sztucznie wprowadzonych błędów. Czyni to dane pochodzące od jednego użytkownika bezużytecznymi, ale zebrane masowo i „połączone” w systemie przetwarzania dają się „odszumić”. Pozwala to poznać ich łączne cechy statystyczne. Apple nie potrzebuje do statystyk indywidualnych danych, a właśnie masowe, pokazujące „trendy”.
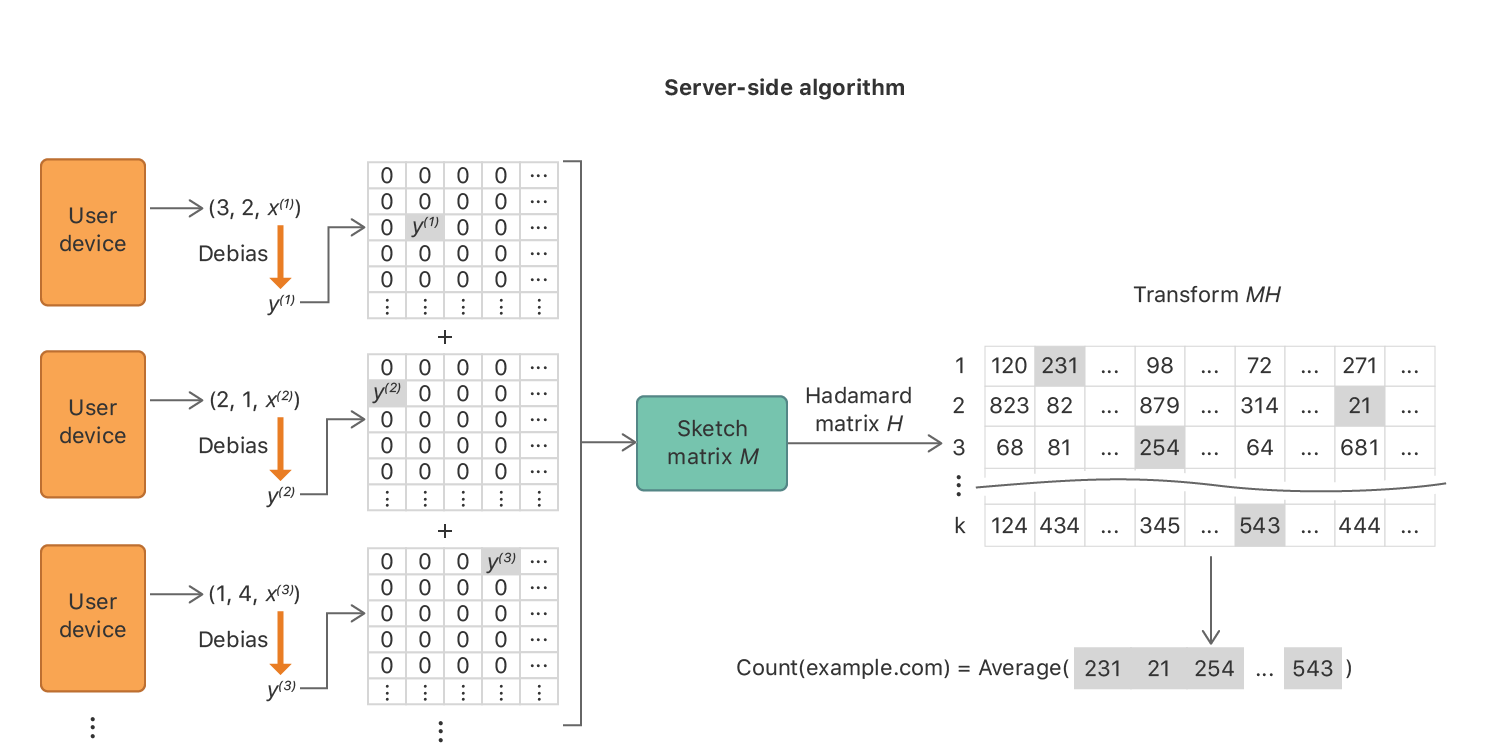
Polecam Wam, choć zerknięcie do artykułu „Learning with Privacy at Scale”. Jeżeli macie problem z angielskim, tłumacz Google wyjątkowo dobrze sobie z nim poradził: „Uczenie się z użyciem prywatności w skali”.
0 komentarzy